Нейронные сети, или Как обучить искусственный интеллект
Машинное обучение является не единственным, но одним из фундаментальных разделов искусственного интеллекта, занимающимся вопросами самостоятельного извлечения знаний интеллектуальной системой в процессе ее работы. Основу машинного обучения составляют так называемые искусственные нейронные сети, принцип работы которых напоминает работу биологических нейронов нервной системы животных и человека.
Технологии искусственного интеллекта все активнее используются в самых различных областях – от производственных процессов до финансовой деятельности. Популярные услуги техгигантов, такие как «Яндекс.Алиса», Google Translate, Google Photos и Google Image Search (AlexNet, GoogleNet) основаны на работе нейронных сетей.
Что такое нейронные сети и как они работают – об этом пойдет речь в статье.
Введение
У искусственного интеллекта множество определений. Под этим термином понимается, например, научное направление, в рамках которого ставятся и решаются задачи аппаратного или программного моделирования тех видов человеческой деятельности, которые традиционно считаются творческими или интеллектуальными, а также соответствующий раздел информатики, задачей которого является воссоздание с помощью вычислительных систем и иных искусственных устройств разумных рассуждений и действий, равно как и свойство систем выполнять «творческие» функции. Искусственный интеллект уже сегодня прочно вошел в нашу жизнь, он используется так или иначе во многих вещах, которые нас окружают – от смартфонов до холодильников, и сферах деятельности компании многих направлений – от IT и банков до тяжелого производства, стремятся использовать последние разработки для повышения эффективности. Данная тенденция будет лишь усиливаться в будущем.
Машинное обучение является не единственным, но одним из основных разделов, фундаментом искусственного интеллекта, занимающимся вопросами самостоятельного извлечения знаний интеллектуальной системой в процессе ее работы. Зародилось это направление еще в середине XX века, однако резко возросший интерес направление получило с существенным развитием области математики, специализирующейся на нейронных сетях, после недавнего изобретения эффективных алгоритмов обучения таких сетей. Идея создания искусственных нейронных сетей была перенята у природы. В качестве примера и аналога была использована нервная система как животного, так и человека. Принцип работы искусственной нейронной сети соответствует алгоритму работы биологических нейронов.
Нейрон – вычислительная единица, получающая информацию и производящая над этой информацией какие-либо вычисления.
Нейроны являются простейшей структурной единицей любой нейронной сети, из их множества, упорядоченного некоторым образом в слои, а в конечном счете – во всю сеть, состоят все сети. Все нейроны функционируют примерно одинаковым образом, однако бывают некоторые частные случаи нейронов, выполняющих специфические функции. Три основных типа нейронов:

Входной – слой нейронов, получающий информацию (синий цвет на рис. 1).
Скрытый – некоторое количество слоев, обрабатывающих информацию (красный цвет на рис. 1).
Выходной – слой нейронов, представляющий результаты вычислений (зеленый цвет на рис. 1).
Помимо самих нейронов существуют синапсы. Синапс – связь, соединяющая выход одного нейрона со входом другого. Во время прохождения сигнала через синапс сигнал может усиливаться или ослабевать. Параметром синапса является вес (некоторый коэффициент, может быть любым вещественным числом), из-за которого информация, передающаяся от одного нейрона к другому, может изменяться. При помощи весов входная информация проходит обработку — и после мы получаем результат.

На рис. 2 изображена математическая модель нейрона. На вход подаются числа (сигналы), после они умножаются на веса (каждый сигнал – на свой вес) и суммируются. Функция активации высчитывает выходной сигнал и подает его на выход.
Сама идея функции активации также взята из биологии. Представьте себе ситуацию: вы подошли и положили палец на конфорку варочной панели. В зависимости от сигнала, который при этом поступит от пальца по нервным окончаниям в мозг, в нейронах вашего мозга будет принято решение: пропускать ли сигнал дальше по нейронным связям, давая посыл мышцам отдернуть палец от горячей конфорки, или не пропускать сигнал, если конфорка холодная и палец можно оставить. Математический аналог функции активации имеет то же назначение. Таким образом, функция активации позволяет проходить или не проходить сигналам от нейрона к нейронам в зависимости от информации, которую они передают. Т.е. если информация является важной, то функция пропускает ее, а если информации мало или она недостоверна, то функция активации не позволяет ей пройти дальше.

В таблице 1 представлены некоторые виды активационных функций нейрона. Простейшей разновидностью функции активации является пороговая. Как следует из названия, ее график представляет из себя ступеньку. Например, если поступивший в нейрон суммарный сигнал от предыдущих нейронов меньше 0, то в результате применения функции активации сигнал полностью «тормозится» и дальше не проходит, т.е. на выход данного нейрона (и, соответственно, входы последующих нейронов) подается 0. Если же сигнал >= 0, то на выход данного нейрона подается 1.
Функция активации должна быть одинаковой для всех нейронов внутри одного слоя, однако для разных слоев могут выбираться разные функции активации. В искусственных нейронных сетях выбор функции обуславливается областью применения и является важной исследовательской задачей для специалиста по машинному обучению.
Нейронные сети набирают все большую популярность и область их использования также расширяется. Список некоторых областей, где применяются искусственные нейронные сети:
- Ввод и обработка информации. Распознавание текстов на фотографиях и различных документах, распознавание голосовых команд, голосовой ввод текста.
- Безопасность. Распознавание лиц и различных биометрических данных, анализ трафика в сети, обнаружение подделок.
- Интернет. Таргетинговая реклама, капча, составление новостных лент, блокировка спама, ассоциативный поиск информации.
- Связь. Маршрутизация пакетов, сжатие видеоинформации, увеличение скорости кодирования и декодирования информации.
Помимо перечисленных областей, нейронные сети применяются в робототехнике [1], компьютерных и настольных играх, авионике, медицине, экономике, бизнесе и в различных политических и социальных технологиях, финансово-экономическом анализе.
Архитектуры нейронных сетей
Архитектур нейронных сетей большое количество, и со временем появляются новые. Рассмотрим наиболее часто встречающиеся базовые архитектуры.
Персептрон
Персептрон – это простейшая модель нейросети, состоящая из одного нейрона. Нейрон может иметь произвольное количество входов (на рис. 3 изображен пример вида персептрона с четырьмя входами), а один из них обычно тождественно равен 1. Этот единичный вход называют смещением, его использование иногда бывает очень удобным. Каждый вход имеет свой собственный вес. При поступлении сигнала в нейрон, как и было описано выше, вычисляется взвешенная сумма сигналов, затем к сигналу применяется функция активации и сигнал передается на выход. Такая простая на первый взгляд сеть, всего из одного-единственного нейрона, способна, тем не менее, решать ряд задач: выполнять простейший прогноз, регрессию данных и т.п., а также моделировать поведение несложных функций. Главное для эффективности работы этой сети – линейная разделимость данных.

Для читателей, немного знакомых с таким разделом как логика, будут знакомы логическое И (умножение) и логическое ИЛИ (сложение). Это булевы функции, принимающие значение, равное 0, всегда, кроме одного случая, для умножения, и, наоборот, значения, равные 1, всегда, кроме одного случая, для сложения. Для таких функций всегда можно провести прямую (или гиперплоскость в многомерном пространстве), отделяющие 0 значения от 1. Это и называют линейной разделимостью объектов. Тогда подобная модель сможет решить поставленную задачу классификации и сформировать базовый логический элемент. Если же объекты линейно неразделимы, то сеть из одного нейрона с ними не справится. Для этого существуют более сложные архитектуры нейронных сетей, в конечном счете, тем не менее, состоящие из множества таких персептронов, объединенных в слои.
Многослойный персептрон
Слоем называют объединение нейронов, на схемах, как правило, слои изображаются в виде одного вертикального ряда (в некоторых случаях схему могут поворачивать, и тогда ряд будет горизонтальным). Многослойный персептрон является обобщением однослойного персептрона. Он состоит из некоторого множества входных узлов, нескольких скрытых слоев вычислительных
нейронов и выходного слоя (см. рис. 4).

Отличительные признаки многослойного персептрона:
- Все нейроны обладают нелинейной функцией активации, которая является дифференцируемой.
- Сеть достигает высокой степени связности при помощи синаптических соединений.
- Сеть имеет один или несколько скрытых слоев [4].
Такие многослойные сети еще называют глубокими. Эта сеть нужна для решения задач, с которыми не может справиться персептрон. В частности, линейно неразделимых задач. В действительности, как следствие из теоремы Колмогорова, именно многослойный персептрон является единственной универсальной нейронной сетью, универсальным аппроксиматором, способным решить любую задачу. Возможно, не самым эффективным способом, который могли бы обеспечить более узкопрофильные нейросети, но все же решить. Именно поэтому, если исследователь не уверен, нейросеть какого вида подходит для решения стоящей перед ним задачи, он выбирает сначала многослойный персептрон.
Сверточная нейронная сеть (convolution neural network)
Сверточная нейронная сеть – сеть, которая обрабатывает передаваемые данные не целиком, а фрагментами. Данные последовательно обрабатываются, а после передаются дальше по слоям. Сверточные нейронные сети состоят из нескольких типов слоев: сверточный слой, субдискретизирующий слой, слой полносвязной сети (когда каждый нейрон одного слоя связан с каждым нейроном следующего – полная связь). Слои свертки и подвыборки (субдискретизации) чередуются и их набор может повторяться несколько раз (см. рис. 5). К конечным слоям часто добавляют персептроны, которые служат для последующей обработки данных [5].

Название архитектура сети получила из-за наличия операции свёртки, суть которой в том, что каждый фрагмент изображения умножается на матрицу (ядро) свёртки поэлементно, а результат суммируется и записывается в аналогичную позицию выходного изображения. Необходимо это для перехода от конкретных особенностей изображения к более абстрактным деталям, и далее – к
ещё более абстрактным, вплоть до выделения понятий высокого уровня (присутствует ли что-либо искомое на изображении).
Сверточные нейронные сети решают следующие задачи:
- Классификация. Пример: нейронная сеть определяет, что или кто находится на изображении.
- Детекция. Пример: нейронная сеть определяет, что/кто и где находится на изображении.
- Сегментация. Пример: нейронная сеть может определить каждый пиксель изображения и понять, к чему он относится.
Описанные сети относятся к сетям прямого распространения. Наряду с ними существуют нейронные сети, архитектуры которых имеют в своем составе связи, по которым сигнал распространяется в обратную сторону.
Рекуррентная нейронная сеть
Рекуррентная нейронная сеть – сеть, соединения между нейронами которой образуют ориентированный цикл. Т.е. в сети имеются обратные связи. При этом информация к нейронам может передаваться как с предыдущих слоев, так и от самих себя с предыдущей итерации (задержка). Пример схемы первой рекуррентной нейронной сети (НС Хопфилда) представлен на рис. 6.

Характеристики сети:
- Каждое соединение имеет свой вес, который также является приоритетом.
- Узлы подразделяются на два типа: вводные (слева) и скрытые (1, 2, … K).
- Информация, находящаяся в нейронной сети, может передаваться как по прямой, слой за слоем, так и между нейронами.
Такие сети еще называют «памятью» (в случае сети Хопфилда – автоассоциативной; бывают также гетероассоциативные (сеть Коско – развитие сети Хопфилда) и другие). Почему? Если подать данной сети на вход некие «образцы» – последовательности кодов (к примеру, 1000001, 0111110 и 0110110) — и обучить ее на запоминание этих образцов, настроив веса синапсов сети определенным образом при помощи правила Хебба [3], то затем, в процессе функционирования, сеть сможет «узнавать» запомненные образы и выдавать их на выход, в том числе исправляя искаженные поданные на вход образы. К примеру, если после обучения такой сети я подам на вход 1001001, то сеть узнает и исправит запомненный образец, выдав на выходе 1000001. Правда, эта нейронная сеть не толерантна к поворотам и сдвигам образов, и все же для первой нейронной сети своего класса сеть весьма интересна.
Таким образом, особенность рекуррентной нейронной сети состоит в том, что она имеет «области внимания». Данная область позволяет задавать фрагменты передаваемых данных, которым требуется усиленная обработка.
Информация в рекуррентных сетях со временем теряется со скоростью, зависящей от активационных функций. Данные сети на сегодняшний день нашли свое применение в распознавании и обработке текстовых данных. Об этом речь пойдет далее.
Самоорганизующаяся нейронная сеть
Пример самоорганизующейся нейронной сети – сеть Кохонена. В процессе обучения осуществляется адаптация сети к поставленной задаче. В представленной сети (см. рис. 7) сигнал идет от входа к выходу в прямом направлении. Структура сети имеет один слой нейронов, которые не имеют коэффициентов смещения (тождественно единичных входов). Процесс обучения сети происходит при помощи метода последовательных приближений. Нейронная сеть подстраивается под закономерности входных данных, а не под лучшее значение на выходе. В результате обучения сеть находит окрестность, в которой находится лучший нейрон. Сеть функционирует по принципу «победитель получает все»: этот самый лучший нейрон в итоге на выходе будет иметь 1, а остальные нейроны, сигнал на которых получился меньше, 0. Визуализировать это можно так: представьте, что правый ряд нейронов, выходной, на
рис. 7 – это лампочки. Тогда после подачи на вход сети данных после их обработки на выходе «зажжется» только одна лампочка, указывающая, куда относится поданный объект. Именно поэтому такие сети часто используются в задачах кластеризации и классификации.

Алгоритмы обучения нейронных сетей
Чтобы получить решение поставленной задачи с использованием нейронной сети, вначале требуется сеть обучить (рис. 8). Процесс обучения сети заключается в настройке весовых коэффициентов связей между нейронами.

Алгоритмы обучения для нейронной сети бывают с учителем и без.
- С учителем: предоставление нейронной сети некоторой выборки обучающих примеров. Образец подается на вход, после происходит обработка внутри нейронной сети и рассчитывается выходной сигнал, сравнивающийся с соответствующим значением целевого вектора (известным нам «правильным ответом» для каждого из обучающих примеров). Если ответ сети не совпадает с требуемым, производится коррекция весов сети, напрямую зависящая от того, насколько отличается ответ сети от правильного (ошибка). Правило этой коррекции называется правилом Видроу-Хоффа и является прямой пропорциональностью коррекции каждого веса и размера ошибки, производной функции активации и входного сигнала нейрона. Именно после изобретения и доработок алгоритма распространения этой ошибки на все нейроны скрытых слоев глубоких нейронных сетей эта область искусственного интеллекта вернула к себе интерес.
- Без учителя: алгоритм подготавливает веса сети таким образом, чтобы можно было получить согласованные выходные векторы, т.е. предоставление достаточно близких векторов будет давать похожие выходы. Одним из таких алгоритмов обучения является правило Хебба, по которому настраивается перед работой матрица весов, например, рекуррентной сети Хопфилда.
Рассмотрим теперь, какие архитектуры сетей являются наиболее востребованными сейчас, каковы особенности использования нейросетей на примерах известных крупных проектов.
Рекуррентные сети на примерах Google и «Яндекса»
Уже упоминавшаяся выше рекуррентная нейронная сеть (RNN) – сеть, которая обладает кратковременной «памятью», из-за чего может быстро производить анализ последовательностей различной длины. RNN разбивает потоки данных на части и производит оценку связей между ними.
Сеть долговременной краткосрочной памяти (Long Shortterm Memory – LSTM) – сеть, которая появилась в результате развития RNN-сетей. Это интересная модификация RNN-сетей, позволяющая сети не просто «держать контекст», но и умеющая «видеть» долговременные зависимости. Поэтому LSTM подходит для прогнозирования различных изменений при помощи экстраполяции (выявление тенденции на основе данных), а также в любых задачах, где важно умение «держать контекст», особенно хорошо подвластное для данной нейросети.
Форма рекуррентных нейронных сетей представляет собой несколько повторяющихся модулей. В стандартном виде эти модули имеют простую структуру. На рисунке 9 изображена сеть, которая имеет в одном из слоев гиперболический тангенс в качестве функции активации.

LSTM также имеет цепочечную структуру. Отличие состоит в том, что сеть имеет четыре слоя, а не один (рис. 10). Главным отличием LSTM-сети является ее клеточное состояние (или состояние ячейки), которое обозначается горизонтальной линией в верхней части диаграммы и по которой проходит информация (рис. 11). Это самое состояние ячейки напоминает ленту конвейера: она проходит напрямую через всю цепочку, участвуя в некоторых преобразованиях. Информация может как «течь» по ней, не подвергаясь изменениям, так и быть подвергнута преобразованиям со стороны нейросети [7]. (Представьте себе линию контроля на конвейере: изделия продвигаются на ленте перед сотрудником контроля, который лишь наблюдает за ними, но если ему что-то покажется важным или подозрительным, он может вмешаться).



LSTM имеет способность удалять или добавлять информацию к клеточному состоянию. Данная способность осуществляется при помощи вентилей, которые регулируют процессы взаимодействия с информацией. Вентиль – возможность выборочно пропускать информацию. Он состоит из сигмоидного слоя нейронной сети и операции поточечного умножения (рис. 12).

Сигмоидный слой (нейроны с сигмоидальной функцией активации) подает на выход числа между нулем и единицей, описывая таким образом, насколько каждый компонент должен быть пропущен сквозь вентиль. Ноль – «не пропускать вовсе», один – «пропустить все». Таких «фильтров» в LSTM-сети несколько. Для чего сети нужна эта способность: решать, что важно, а что нет? Представьте себе следующее: сеть переводит предложение и в какой-то момент ей предстоит перевести с английского языка на русский, скажем, местоимение, прилагательное или причастие. Для этого сети необходимо, как минимум, помнить род и/или число предыдущего существительного, к которому переводимое слово относится. Однако как только мы встретим новое существительное, род предыдущего можно забыть. Конечно, это очень упрощенный пример, тем не менее, он позволяет понять трудность принятия решения: какая информация еще важна, а какую уже можно забыть. Иначе говоря, сети нужно решить, какая информация будет храниться в состоянии ячейки, а затем – что на выходе из нее будет выводить.
Примеры использования нейронных сетей
Мы рассмотрели основные типы нейронных систем и познакомились с принципами их работы. Остановимся теперь на их практическом применении в системах Google Translate, «Яндекс.Алиса», Google Photos и Google Image Search (AlexNet, GoogleNet).
LSTM в Google Translate
Google-переводчик в настоящее время основан на методах машинного обучения и использует принцип работы LSTM-сетей. Система производит вычисления, чтобы понять значение слова или фразы, основываясь на предыдущих значениях в последовательности (контексте). Такой алгоритм помогает системе понимать контекст предложения и верно подбирать перевод среди различных вариантов. Еще несколько лет назад Google Translate работал на основе статистического машинного перевода – это разновидность перевода, где перевод генерируется на основе статистических моделей (бывают: по словам, по фразам, по синтаксису и т.д.), а параметры этих моделей являются результатами анализа корпусов текстов двух выбранных для перевода языков. Эти статистические модели обладали большим быстродействием, однако их эффективность ниже. Общий прирост качества перевода после внедрения системы на основе нейросетей в Google-переводчик составил, казалось бы, не очень много – порядка 10%, однако для отдельных языковых пар эффективность перевода достигла 80-90%, вплотную приблизившись к оценкам качества человеческого перевода. «Платой» за такое качество перевода является сложность построения, обучения и перенастройки системы на основе нейросети: она занимает недели. Вообще для современных глубоких нейронных сетей, использующихся в таких крупных проектах, в порядке вещей обучение, занимающее дни и недели.
Рассмотрим LSTM-сеть переводчика (GNMT) подробнее. Нейронная сеть переводчика имеет разделение на два потока (см. рис. 13). Первый поток нейронной сети (слева) является анализирующим и состоит из восьми слоев. Данный поток помогает разбивать фразы или предложения на несколько смысловых частей, а после производит их анализ. Сеть позволяет читать предложения в двух направлениях, что помогает лучше понимать контекст. Также она занимается формированием модулей внимания, которые позволяют второму потоку определять ценности отдельно взятых смысловых фрагментов.

Второй поток нейронной сети (справа) является синтезирующим. Он позволяет вычислять самый подходящий вариант для перевода, основываясь на контексте и модулях внимания (показаны голубым цветом).
В системе нейронной сети самым маленьким элементом является фрагмент слова. Это позволяет сфокусировать вычислительную мощность на контексте предложения, что обеспечивает высокую скорость и точность переводчика. Также анализ фрагментов слова сокращает риски неточного перевода слов, которые имеют суффиксы, префиксы и окончания [8].
LSTM в «Яндекс.Алисе»
Компания «Яндекс» также использует нейросеть типа LSTM в продукте «Яндекс.Алиса». На рисунке 14 изображено взаимодействие пользователя с системой. После вопроса пользователя информация передается на сервер распознавания, где она преобразуется в текст. Затем текст поступает в классификатор интентов (интент (от англ. intent) – намерение, цель пользователя, которое он вкладывает в запрос), где при помощи машинного обучения анализируется. После анализа интентов они поступают на семантический теггер (tagger) – модель, которая позволяет выделить полезную и требующуюся информацию из предложения. Затем полученные результаты структурируются и передаются в модуль dialog manager, где обрабатывается полученная информация и генерируется ответ.

LSTM-сети применяются в семантическом теггере. В этом модуле используются двунаправленные LSTM с attention. На этом этапе генерируется не только самая вероятная гипотеза, потому что в зависимости от диалога могут потребоваться и другие. От состояния диалога в dialog manager происходит повторное взвешивание гипотез. Сети с долговременной памятью помогают лучше вести диалог с пользователем, потому что могут помнить предыдущие сообщения и более точно генерировать ответы, а также они помогают разрешать много проблемных ситуаций. В ходе диалога нейронная сеть может убирать слова, которые не несут никакой важной информации, а остальные анализировать и предоставлять ответ [9].
Для примера на рис. 14 результат работы системы будет следующим. Сначала речь пользователя в звуковом формате будет передана на сервер распознавания, который выполнит лексический анализ (т.е. переведет сказанное в текст и разобьет его на слова – лексемы), затем классификатор интентов выполнит уже роль семантического анализа (понимание смысла того, что было сказано; в данном случае – пользователя интересует погода), а семантический теггер выделит полезные элементы информации: теггер выдал бы, что завтра – это дата, на которую нужен прогноз погоды. В итоге данного анализа запроса пользователя будет составлено внутреннее представление запроса – фрейм, в котором будет указано, что интент – погода, что погода нужна на +1 день от текущего дня, а где – неизвестно. Этот фрейм попадет в диалоговый менеджер, который хранит тот самый контекст беседы и будет принимать на основе хранящегося контекста решение, что делать с этим запросом. Например, если до этого беседа не происходила, а для станции с «Яндекс.Алисой» указана геолокация г.Москва, то менеджер получит через специальный интерфейс (API) погоду на завтра в Москве, отправит команду на генерацию текста с этим прогнозом, после чего тот будет передан в синтезатор речи помощника. Если же Алиса до этого вела беседу с пользователем о достопримечательностях Парижа, то наиболее вероятно, что менеджер учтет это и либо уточнит у пользователя информацию о месте, либо сразу сообщит о погоде в Париже. Сам диалоговый менеджер работает на основе скриптов (сценариев обработки запросов) и правил, именуемых form-filling.
Вот такой непростой набор технических решений, методов, алгоритмов и систем кроется за фасадом, позволяющим пользователю спросить и узнать ответ на простой бытовой вопрос или команду.
Свёрточные нейронные сети, используемые для классификации изображений, на примере Google Photos и Google Image Search
Задача классификации изображений – это получение на вход начального изображения и вывод его класса (стол, шкаф, кошка, собака и т.д.) или группы вероятных классов, которая лучше всего характеризует изображение. Для людей это совершенно естественно и просто: это один из первых навыков, который мы осваиваем с рождения. Компьютер лишь «видит» перед собой пиксели изображения, имеющие различный цвет и интенсивность. На сегодня задача классификации объектов, расположенных на изображении, является основной для области компьютерного зрения. Данная область начала активно развиваться с 1970-х, когда компьютеры стали достаточно мощными, чтобы оперировать большими объёмами данных. До развития нейронных сетей задачу классификации изображений решали с помощью специализированных алгоритмов. Например, выделение границ изображения с помощью фильтра Собеля и фильтра Шарра или использование гистограмм градиентов [10]. С появлением более мощных GPU, позволяющих значительно эффективнее обучать нейросеть, применение нейросетей в сфере компьютерного зрения значительно возросло.
В 1988 году Ян Лекун предложил свёрточную архитектуру нейросети, нацеленную на классификацию изображений. А в 2012 году сеть AlexNet, построенная по данной архитектуре, заняла первое место в конкурсе по распознаванию изображений ImageNet, имея ошибку распознавания равную 15,3% [12]. Свёрточная архитектура нейросети использует некоторые особенности биологического распознавания образов, происходящих в мозгу человека. Например, в мозгу есть некоторые группы клеток, которые активируются, если в определённое поле зрения попадает горизонтальная или вертикальная граница объекта. Данное явление обнаружили Хьюбель и Визель в 1962 году [13]. Поэтому, когда мы смотрим на изображение, скажем, собаки, мы можем отнести его к конкретному классу, если у изображения есть характерные особенности, которые можно идентифицировать, такие как лапы или четыре ноги. Аналогичным образом компьютер может выполнять классификацию изображений через поиск характеристик базового уровня, например, границ и искривлений, а затем — с помощью построения более абстрактных концепций через группы сверточных слоев.
Рассмотрим подробнее архитектуру и работу свёрточной нейросети (convolution neural network) на примере нейросети AlexNet (см. рис. 15). На вход подаётся изображение 227х227 пикселей (на рисунке изображено желтым), которое необходимо классифицировать (всего 1000 возможных классов). Изображение цветное, поэтому оно разбито по трём RGB-каналам. Наиболее важная операция – операция свёртки.

Операция свёртки (convolution) производится над двумя матрицами A и B размера [axb] и [cxd], результатом которой является матрица С размера
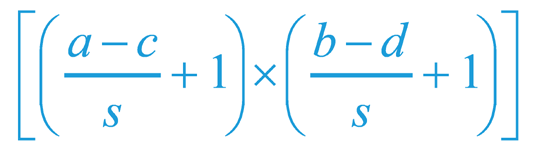
, где s – шаг, на который сдвигают матрицу B. Вычисляется результирующая матрица следующим образом:
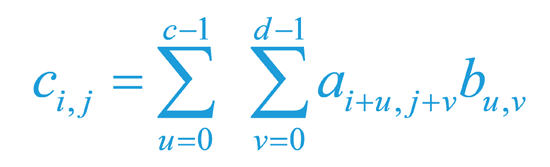
см. рис 16.

Чем больше результирующий элемент ci,j, тем более похожа область матрицы A на матрицу B. A называют изображением, а B – ядром или фильтром. Обычно шаг смещения B равен s = 1. Если увеличить шаг смещения, можно добиться уменьшения влияния соседних пикселей друг на друга в сумме (уменьшить рецептивное поле восприятия нейросети), в подавляющем большинстве случаев шаг оставляют равным 1. На рецептивное поле также влияет и размер ядра свёртки. Как видно из рис. 16, при свёртке результат теряет в размерности по сравнению с матрицей A. Поэтому, чтобы избежать данного явления, матрицу A дополняют ячейками (padding)[15]. Если этого не сделать, данные при переходе на следующие слои будут теряться слишком быстро, а информация о границах слоя будет неточной.
Таким образом, свёртка позволяет одному нейрону отвечать за определённый набор пикселей в изображении. Весовыми коэффициентами являются коэффициенты фильтра, а входными переменными – интенсивность свечения пикселя плюс параметр смещения.
Данный пример свёртки (см. рис. 16) был одномерным и подходит, например, для черно-белого изображения. В случае цветного изображения операция свёртки происходит следующим образом: в один фильтр включены три ядра, для каждого канала RGB соответственно, над каждым каналом операция свёртки происходит идентично примеру выше, затем три результирующие матрицы поэлементно складываются – и получается результат работы одного
фильтра – карта признаков.
Эта на первый взгляд непростая с математической точки зрения процедура нужна для выделения тех самых границ и искривлений – контуров изображения, при помощи которых, по аналогии с мозгом человека, сеть должна понять, что же изображено на картинке. Т.е. на карте признаков будут содержаться выделенные характеристические очертания детектированных объектов. Эта карта признаков будет являться результатом работы чередующихся слоев свертки и пулинга (от англ. pooling, или иначе – subsampling layers). Помните, в разделе описания концепции архитектуры сверточных сетей мы говорили, что эти слои чередуются и их наборы могут повторяться несколько раз (см. рис. 5)? Для чего это нужно? После свертки, как мы знаем, выделяются и «заостряются» некие характеристические черты анализируемого изображения (матрицы пикселей) путем увеличения значений соответствующих ядру ячеек матрицы и «занулению» значений других. При операции субдискретизации, или пулинга, происходит уменьшение размерности сформированных отдельных карт признаков. Поскольку для сверточных нейросетей считается, что информация о факте наличия искомого признака важнее точного знания его координат на изображении, то из нескольких соседних нейронов карты признаков выбирается максимальный и принимается за один нейрон уплотнённой карты признаков меньшей размерности. За счёт данной операции, помимо ускорения дальнейших вычислений, сеть становится также более инвариантной к масштабу входного изображения, сдвигам и поворотам изображений. Данное чередование слоев мы видим и для данной сети AlexNet (см. рис. 15), где слои свертки (обозначены CONV) чередуются с пулингом (обозначены эти слои как POOL), при этом следует учитывать, что операции свертки тем ресурсозатратнее, чем больше размер ядра свертки (матрицы B на рис. 16), поэтому иногда, когда требуется свертка с ядром достаточно большой размерности, ее заменяют на две и более последовательных свертки с ядром меньших размерностей. (Об этом мы поговорим далее.) Поэтому на рис. 15 мы можем увидеть участок архитектуры AlexNet, на котором три слоя CONV идут друг за другом.
Самая интересная часть в сети – полносвязный слой в конце. В этом слое по вводным данным (которые пришли с предыдущих слоев) строится и выводится вектор длины N, где N – число классов, по которым мы бы хотели классифицировать изображение, из них программа выбирает нужный. Например, если мы хотим построить сеть по распознаванию цифр, у N будет значение 10, потому что цифр всего 10. Каждое число в этом векторе представляет собой вероятность конкретного класса. Например, если результирующий вектор для распознавания цифр это [0 0.2 0 0.75 0 0 0 0 0.05], значит существует 20% вероятность, что на изображении «1», 75% вероятность – что «3», и 5% вероятность – что «9». Если мы хотим сеть по распознаванию букв латинского алфавита, то N должно быть равным 26 (без учета регистра), а если и буквы, и цифры вместе, то уже 36. И т.д. Конечно, это очень упрощенные примеры. В сети AlexNet конечная размерность выхода (изображена на рис. 15 зеленым) — 1000, а перед этим идут еще несколько полносвязных слоев с размерностями входа 9216 и выхода 4096 и обоими параметрами 4096 (изображены оранжевым и отмечены FC – full connected — на рисунке).
Способ, с помощью которого работает полносвязный слой, – это обращение к выходу предыдущего слоя (который, как мы помним, должен выводить высокоуровневые карты свойств) и определение свойств, которые больше связаны с определенным классом. Поэтому в результате работы окончания сверточной сети по поданному на вход изображению с лужайкой, на которой, скажем, собака гоняется за птичкой, упрощенно можно сказать, что результатом может являться следующий вывод:
[dog (0.6), bird (0.35), cloud (0.05)].
Свёрточная нейронная сеть GoogleNet
В 2014 году на том же соревновании ImageNet, где была представлена AlexNet, компания Google показала свою свёрточную нейросеть под названием GoogleNet. Отличительная особенность этой сети была в том, что она использовала в 12 раз меньше параметров (почувствуйте масштабы: 5 000 000 против 60 000 000) и её архитектура структурно была не похожа на архитектуру AlexNet, в которой было восемь слоёв, причём данная сеть давала более точный результат – 6,67% ошибки против 16,4%[16].
Разработчики GoogleNet пытались избежать простого увеличения слоёв нейронной сети, потому что данный шаг привёл бы к значительному увеличению использования памяти и сеть была бы больше склонна к перенасыщению при обучении на небольшом и ограниченном наборе примеров.
Проанализируем приём, на который пошли разработчики компании Google для оптимизации скорости и использования памяти. В нейросети GoogleNet свёртка с размером фильтра 7×7 используется один раз в начале обработки изображения, далее максимальный размер – 5×5. Так как количество параметров при свёртке растёт квадратично с увеличением размерности ядра, нужно стараться заменять одну свёртку на несколько свёрток с меньшим размером фильтра, вместе с этим пропустить промежуточные результаты через ReLU (функция активации, возвращающая 0, если сигнал отрицателен, и само значение сигнала, если нет), чтобы внести дополнительную нелинейность. Например, свёртку с размером фильтра 5×5 можно заменить двумя последовательными операциями с размером ядра 3×3. Такая оптимизация позволяет строить более гибкие и глубокие сети. На хранение промежуточных свёрток тратится память, и использовать их более разумно в слоях, где размер карты признаков небольшой. Поэтому в начале сети GoogleNet вместо трёх свёрток 3×3 используется одна 7×7, чтобы избежать избыточного использования памяти.
Схему архитектуры сети целиком мы приводить здесь не будем, она слишком громоздка и на ней трудно что-либо разглядеть, кому это будет интересно, могут ознакомиться с ней на официальном ресурсе. Отличительной особенностью нейросети от компании Google является использование специального модуля – Inception (см. рис. 17). Данный модуль, по своей сути, является небольшой локальной сетью. Идея данного блока состоит в том, что на одну карту признаков накладывается сразу несколько свёрток разного размера, вычисляющихся параллельно. В конце все свёртки объединяются в единый блок. Таким образом, можно из исходной карты признаков извлечь признаки разного размера, увеличив эффективность сети и точность обработки признаков. Однако при использовании данной реализации (см. рис. 17) нужно выполнить колоссальный объём вычислений, между тем, при включении данных модулей друг за другом размерность блока будет только расти. Поэтому разработчики во второй версии добавили свёртки, уменьшающие размерность (см. рис. 18).


Жёлтые свёртки размера 1×1 введены для уменьшения глубины блоков, и благодаря им, значительно снижается нагрузка на память. GoogleNet содержит девять таких Inception-модулей и состоит из 22 слоёв.
Из-за большой глубины сети разработчики также столкнулись с проблемой затухания градиента при обучении (см. описание процедуры обучения нейросети: коррекция весов осуществляется в соответствии со значением ошибки, производной функции активации – градиента – и т.д.) и ввели два вспомогательных модуля классификатора (см. рис. 19)[16]. Данные модули представляют собой выходную часть малой свёрточной сети и уже частично классифицируют объект по внутренним характеристикам самой сети. При обучении нейронной сети данные модули не дают ошибке, распространяющиейся с конца, сильно уменьшиться, так как вводят в середину сети дополнительную ошибку.

Ещё один полезный аспект в архитектуре GoogleNet, по мнению разработчиков, состоит в том, что сеть интуитивно правильно обрабатывает изображение: сначала картинка обрабатывается в разных масштабах, а затем результаты агрегируются[16]. Такой подход больше соответствует тому, как подсознательно выполняет анализ окружения человек.
В 2015 году разработчики из Google представили модифицированный модуль Inception v2, в котором свёртка 5×5 была заменена на две свёртки 3×3, по причинам, приведённым выше, вдобавок потери информации в картах признаков при таком действии происходят незначительные, так как соседние ячейки имеют между собой сильную корреляционную связь [17]. Также, если заменить свёртку 3×3 на две последовательные свёртки 3×1 и 1×3, то это будет на 33% эффективнее, чем стандартная свёртка, а две свёртки 2×2 дадут выигрыш лишь в 11% [17]. Данная архитектура нейросети давала ошибку 5,6%, а потребляла ресурсов в 2,5 раза меньше.
Стоит отметить, что точного алгоритма построения архитектуры нейросети не существует. Разработчики составляют свёрточные нейросети, основываясь на результатах экспериментов и собственном опыте.
Нейронную сеть можно использовать для точной классификации изображений, загруженных в глобальную сеть, либо использовать для сортировки фотографий по определённому признаку в галерее смартфона.
Свёрточная нейронная сеть имеет следующие преимущества: благодаря своей структуре, она позволяет значительно снизить количество весов в сравнении с полносвязанной нейронной сетью, её операции легко поддаются распараллеливанию, что положительно сказывается на скорости обучения и на скорости работы, данная архитектура лидирует в области классификации изображений, занимая первые места на соревновании ImageNet. Из-за того, что для сети более важно наличие признака, а не его место на изображении, она инвариантна к различным сдвигам и поворотам сканируемого изображения.
К недостаткам данной архитектуры можно отнести следующие: состав сети (количество её слоёв, функция активации, размерность свёрток, размерность pooling-слоёв, очередность слоёв и т.п.) необходимо подбирать эмпирически к определённому размеру и виду изображения; сложность обучения: нейросети с хорошим показателем ошибки должны тренироваться на мощных GPU долгое время; и, наверное, главный недостаток – атаки на данные нейросети. Инженеры Google в 2015 году показали, что к картинке можно подмешать невидимый для человеческого зрения градиент, который приведёт к неправильной классификации [18].
Список литературы
1. Vlasov A., Yudin A. Distributed control system in mobile robot application: general approach, realization and usage // Communications in Computer and Information Science. 2011. Т. 156 CCIS. P. 180–192.
2. Яковлев В.Л., Яковлева Г.Л., Власов А.И. Нейросетевые методы и модели при прогнозировании краткострочных и долгосрочных тенденций финансовых рынков // В сборнике: VI Всероссийская конференция «Нейрокомпьютеры и их применение», 2000. С. 372–377.
3. Интеллектуальные технологии на основе искусственных нейронных сетей / М.А. Басараб, Н.С. Коннова. – Москва: Издательство МГТУ им. Н.Э. Баумана, 2017. – 53 с.
4. Солдатова О.П. Нейроинформатика. Курс лекций. СГАУ, 2013. 130 с.
5. Y. LeCun, Y. Bengio. Convolutional Networks for Images, Speech, and Time-Series // The Handbook of Brain Theory and Neural Networks, MIT Press, 1995.
6. Understanding LSTM Networks [Электронный ресурс] URL: https://colah.github.io/posts/2015-08-Understanding-LSTMs/ (Дата обращения 26.03.2020).
7. LSTM – сети долгой краткосрочной памяти [Электронный ресурс] URL: https://habr.com/ru/company/wunderfund/blog/331310/ (Дата обращения 30.03.2020).
8. Как работает нейросеть Google Translate [Электронный ресурс] URL: https://www.cossa.ru/152/196086 (Дата обращения 26.03.2020).
9. Как устроена Алиса. Лекция Яндекса [Электронный ресурс] URL: https://habr.com/ru/company/yandex/blog/349372/ (Дата обращения 26.03.2020).
10. Д.А. Хрящёв. Об одном методе выделения контуров на цифровых изображениях // Вестник АГТУ, 2010. No 2. С. 1-7.
11. LeCun Y., Bottou L., Bengio Y., Haffner P. GradientBased Learning Applied to Document Recognition // Proceedings of the IEEE. 1998. 46 p.
12. Krizhevsky A., Sutskever I., Hinton G. ImageNet Classification with Deep Convolutional Neural Networks // Advances in neural information processing systems, 25 (2). 2012.
13. Hubel D., Wiesel T. Brain mechanisms of vision // Scientific American, 241(3). 1979.
14. Nayak S. Understanding AlexNet [Электронный ресурс] URL: https://www.learnopencv.com/understanding-alexnet/ (Дата обращения 30.03.2020).
15. Dumoulin V., Visin F. A guide to convolution arithmetic for deep learning [Электронный ресурс] URL: https://arxiv.org/pdf/1603.07285.pdf (Дата обращения 30.03.2020).
16. Szegedy C., Liu W., Jia Y., Sermanet P., Reed S., Anguelov D., Erhan D., Vanhoucke V., Rabinovich A. Going deeper with convolutions // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015. P. 1–10.
17. Szegedy C., Vanhoucke V., Ioffe S., Shlens J. Rethinking the Inception Architecture for Computer // IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016 [Электронный ресурс] URL: https://arxiv.org/ pdf/1512.00567.pdf (Дата обращения 30.03.2020).
18. Ian J. Goodfellow, Shlens J., Szegedy C. Explaining and harnessing adversarial examples // Published as a conference paper at ICLR. 2015 [Электронный ресурс] URL: https://arxiv.org/pdf/1412.6572.pdf (Дата обращения 30.03.2020).