Применение методов ИИ в системе поддержки проведения научно-технических экспертиз
Аннотация – Для повышения качества проведения научно-технических экспертиз была создана система, которая автоматизирует процесс проверки документов [1]. Целью данного исследования является усовершенствование алгоритмов анализа текстов для реализованной системы. В данной статье рассматривается задача бинарной классификации документов, предоставляемых налогоплательщиком, с помощью технологий машинного обучения. В результате исследования произведен сравнительный анализ и определены наиболее эффективные алгоритмы машинного обучения.
- Введение
Повсеместная разработка и внедрение инновационных технологий в различных областях науки и техники поощряется государством в целях экономического развития. Данная поддержка может осуществляться прямым финансированием или же косвенным стимулированием. В российском налоговом законодательстве косвенное стимулирование реализуется в виде налоговых льгот. Например, пунктом 7 статьи 262 НК РФ установлено, что “Налогоплательщик, осуществляющий расходы на научные исследования или опытно-конструкторские разработки по перечню научных исследований, установленному Правительством Российской Федерации, вправе включать эти расходы в состав прочих расходов отчетного (налогового) периода, в котором были завершены такие исследования или разработки (отдельные этапы работ), или первоначальную стоимость амортизированных нематериальных активов в размере фактических затрат с использованием коэффициента 1,5.” [2].
Данная налоговая льгота обеспечивает экономию по налогу на прибыль организаций, выполняющих работы, обладающие научной новизной для развития национальной науки и техники в целом. Однако существует множество случаев, когда налогоплательщик неправомерно применял данную налоговую льготу. Выявление неправомерности применения налоговой льготы, предусмотренной 262 статьей НК РФ, осуществляется путем налоговой проверки предоставляемых налогоплательщиками отчетов о проведении НИОКР. При этом проверка осуществляется в двух направлениях:
- анализ финансовой документации, сопровождающей реализацию налогоплательщиком проектов, заявленных как НИОКР. Проверка финансовых документов позволяет налоговому инспектору определить правильность расчета налогов с учетом соответствующих льгот и преференций;
- экспертиза научно-технических отчетов с целью определения признаков научной новизны и инновационности НИОКР, соответствия выполняемых работ важным научно-техническим направлениям, установленным правительством.
Для повышения качества проведения научно-технических экспертиз была создана система, которая автоматизирует процесс экспертизы отчетной документации, предоставляемой налогоплательщиком в налоговые органы для подтверждения правомерности применения налоговой льготы [1]. В данной системе налогоплательщику предоставляется возможность через интернет-приложение заполнить чек-лист в веб-браузере, который позволит провести первоначальную проверку представляемой информации. Данный онлайн-сервис будет интегрирован с другими сервисами цифровой платформы Федеральной налоговой службы (ФНС). Это позволит осуществлять взаимодействие налогоплательщика с инспекцией ФНС, используя защищенные интернет-каналы для передачи больших объемов текстовой информации, сосредоточенной в научно-технических отчетах. Разработанный сервис [1] должен предоставлять возможность не только анализировать информацию, заполняемую налогоплательщиком в формате «Чек-листа», но и получать научно-технические отчеты о выполненных НИР/НИОКР. Решение этой задачи невозможно без применения методов искусственного интеллекта для содержательного анализа текстов отчетов на предмет выявления обязательных признаков НИР/НИОКР, что позволит существенно повысить эффективность проведения научно-технических экспертиз для принятия решения по правомерности применяемых налоговых льгот.
Целью данного исследования является усовершенствование алгоритмов анализа текстов для системы поддержки проведения научно-технических экспертиз. Для достижения данной цели рассматривается задача бинарной классификации документов, предоставляемых налогоплательщиком, с помощью технологий машинного обучения. В качестве конечного результата исследования, будут определены наиболее эффективные, с точки зрения технико-экономических показателей, алгоритмы машинного обучения.
- Литературный обзор
В настоящее время для решения задачи классификации текста уже используется достаточно большое количество подходов. Например, в исследовании [3] авторы проводят сравнительный анализ таких методов, как метод опорных векторов, метод Байеса и k-ближайших соседей для решения задачи бинарной классификации тональности текста. Для векторного представления текстовой информации использовался метод «мешок слов». В качестве данных авторы использовали русскоязычные посты в Twitter, разделенные на положительную и негативную тональность.
Примерами похожей работы является исследование [4,5]. В [4] для определения тональности текста на примере постов в Twitterавторы сравнивали следующие модели: логистическая регрессия, случайный лес, наивный байесовский метод, дерево решений и метод k-ближайших соседей. В [5] авторы рассматривают задачу классификации эмоциональной окраски отзывов о фильме, используя метод Байеса и «мешок слов».
В исследовании [6] авторы рассматривают уже многоклассовую задачу классификации текста. Авторы сравнивают качество классификации при разных подходах предобработки текста: лемматизации (объединение слов с одним и тем же корнем или леммой, но с разными склонениями или производными значениями для дальнейшего анализа как элемента) и стемминге (процесс нахождения основы слова для заданного исходного слова). Более того, авторы анализируют разные подходы к векторизации данных: TF-IDF и Glove. Стоит отметить, что в работе используется набор данных с англоязычным описанием товаров для животных. Для снижения размерности признаков авторы выяснили, что метод RFEоказался лучшим методом для отбора признаков.
Однако исследование [7] представляет другой подход, используя нейронные сети для задачи классификации тональности коротких русскоязычных текстов. Для построения моделей нейронных сетей исследовались следующие архитектуры: многослойный персептрон, сети с долгой краткосрочной памятью (Long Short Term Memory) и управляемые рекуррентные нейроны (GRU). В результате экспериментов наилучшее качество было достигнуто при использовании GRU и векторного представления модели Word2Vec, обученной на корпусе WikiRuscorpora.
Стоит также упомянуть исследования модели BERT для решения задачи классификации сообщений на русском языке [8]. Однако главным недостатком BERT для русскоязычных текстов является ограничение в 512 токенов. Решение данной проблемы предложили авторы в работе [9]. Как правило, важнейшая информация в тексте содержится в начале и конце. Поэтому были проанализированы методы усечения текста. В результате было выявлено, что наилучшее качество классификации демонстрирует метод усечения с использованием последних 512 токенов. Однако нейронные сети следует применять только при достаточно большом и полном наборе данных.
В целом, вышеописанные исследования в основном проводились на коротких текстах. Однако стоит упомянуть работу [10], где авторы исследуют задачу классификации диссертаций по специальностям. В результате был протестирован набор данных с помощью таких методов классификации, как случайный лес, k-ближайших соседей, логистическая регрессия, дерево решений, метод опорных векторов и многослойный персептрон.
Таким образом, для решения бинарной задачи классификации текста подходят следующие методы: дерево решений, случайный лес, логистическая регрессия, k-ближайших соседей, метод опорных векторов, метод Байеса и многослойный персептрон. Векторное представление текстовой информации в основном моделируется с помощью методов BOW и TF-IDF. Главным недостатком двух методов векторизации является проблема большой размерности признакового пространства, поэтому данные методы часто используются с методами снижения размерности. Признаковое пространство составляется на основе корпуса, который был использован для обучения модели. То есть модель не будет учитывать слова, которых не было в тренировочном наборе.
- Методы
Алгоритмы машинного обучения не могут работать напрямую с необработанным текстом: его необходимо преобразовать в числовое представление. В рамках данного исследования были реализованы несколько подходов представления текстов в признаки.
Bag-of-Words (BOW) — это представление текста, которое описывает присутствие слов в документе. Модель создает словарь всех уникальных слов в корпусе и подсчитывает, встречается ли определенное слово в тексте. Однако при таком вычленении признаков из текста теряется информация о порядке слов или структуре слов.
Похожий подход представляет метод векторизации данных TF-IDF (Term frequency-inverse document frequency). В отличие от первого подхода, счетчик в описании признаков заменяется на значение TF-IDF:
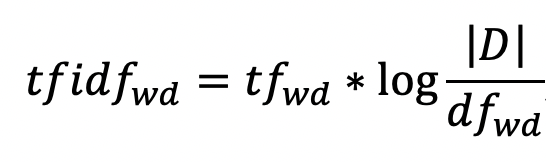
где – отношение числа вхождений слова в документе к общему числу слов в данном документе;
– число документов, содержащих данное слово;
– число документов в коллекции.
Еще одним из популярных методов извлечения признаков из текста является встраивание слов. Это метод, при котором каждому слову сопоставляется вектор действительных чисел. Основная идея вложения слов в том, что слова, появляющиеся в схожем контексте, будут ближе в векторном пространстве.
Для извлечения признака одного текста можно воспользоваться двумя подходами: вектор каждого текста будет равен среднему из векторов входящих в него слов, или же брать в качестве признака средневзвешенное значение векторов слов.
В данной статье мы использовали предобученную модель Word2Vec с сайта RusVectores [10]. Данная модель обучена на текстовом корпусе НКРЯ и Википедии за ноябрь 2021 года. В качестве весов для слов мы будем использовать значение IDF из векторного представления текста TF-IDF.
В результате исследования литературы для решения задачи классификации текста были выбраны следующие методы:
- логистическая регрессия;
- дерево решений;
- случайный лес;
- метод опорных векторов;
- k-ближайших соседей;
- многослойный перцептрон.
Кратко опишем некоторые методы.
Одним из классических и линейных классификаторов является логистическая регрессия. Она использует логистическую функцию для оценки вероятности того, что объект принадлежит к определенному классу, и на основе этой оценки делает предсказание.
Метод дерева решений (Decision Tree, DT) является одним из наиболее популярных алгоритмов машинного обучения для классификации. Он позволяет построить дерево, где каждый узел представляет собой признак, каждая ветвь – возможное значение признака, а листья – прогнозируемый класс. Суть метода заключается в том, чтобы выбирать оптимальный признак для разбиения данных на каждом шаге построения дерева таким образом, чтобы уменьшить неопределенность в классификации.
Случайный лес (Random Forest, RF) — это алгоритм машинного обучения, который основан на построении ансамбля деревьев решений. При классификации нового объекта каждое дерево в лесу даёт свой ответ, а финальное решение принимается на основе голосования деревьев.
Метод опорных векторов (Support Vector Machines, SVM) — это линейный метод машинного обучения для решения задач классификации и регрессии. Он основывается на поиске оптимальной разделяющей гиперплоскости между классами, которая максимально увеличивает зазор (margin) между ними. Опорными векторами являются примеры обучающей выборки, которые находятся на границе разделения классов и определяют положение разделяющей гиперплоскости.
Метод k-ближайших соседей (k Nearest Neighbors, KNN) – это метод машинного обучения, который используется для классификации объектов. Суть метода заключается в том, что каждый объект классифицируется на основе классов k-ближайших к нему объектов в пространстве признаков. Количество ближайших соседей k выбирается заранее и является параметром метода. Объект относится к тому классу, который наиболее часто встречается среди k-ближайших соседей.
- Анализ и предобработка данных
В работе исследуется набор документов, которые предоставлялись налогоплательщиком для проведения экспертизы. Предоставляемые документы можно разделить на два класса по признаку принадлежности работ, описываемых в отчетных документах, к НИР/НИОКР.
- Анализируемый отчет является отчетом о проведении НИР/НИОКР.
- Не является.
Обозначим первый класс анализируемых отчетов за положительный, т.е. имеющих признаки НИР/НИОКР, а второй за отрицательный, в который попадают отчеты, не имеющие признаков НИР/НИОКР. В собранном наборе данных было представлено 26 положительных отчетов и 23 отрицательных. Таким образом, ставится задача бинарной классификации документов.
На первом этапе исследования осуществлялось считывание всех файлов с анализируемыми отчетами и проводилась ручная разметка категорий документов. В необработанных текстах часто встречаются слова, не имеющие смысловой нагрузки. Так как извлечение признаков из текстов порождает большую размерность признакового пространства, то следует избавиться от слов, не несущих смысловой нагрузки. Следующим этапом является базовая предобработка текста. Во-первых, проводится токенизация текста. Во-вторых, мы приводим все слова к нижнему регистру и леммантизируем текст с помощью библиотеки pymorphy2.
Последним этапом предобработки текстов является удаление стоп-слов, цифр и знаков пунктуации. Однако данная предобработка будет использоваться только для последующего применения методов векторного представления текста Bag-of-Words и TF-IDF. Для подхода с векторным представлением слов с помощью модели Word2Vec будет проводиться дополнительный этап предобработки текста в виде автоматической морфологической разметки (POS – tagging). То есть для каждого слова будет определена его часть речи и грамматическая характеристика с приписыванием ему соответствующего тега.
Заключительным этапом будет выбор метрик качества классификации. Так как мы рассматриваем задачу классификации с двумя классами, то в качестве метрики целесообразно использовать метрику . Для этого будет высчитываться мера для каждого класса, а потом высчитываться среднее по всем классам.
- Результаты компьютерного моделирования
Для того, чтобы обосновать выбор методов машинного обучения для задачи классификации текстов, предоставляемых на экспертизу, необходимо провести компьютерные эксперименты. То есть на основе обработанных текстов провести обучение модели и определить точность классификации на тестовом наборе. Для реализации всех классификаторов будем пользоваться библиотекой scikit-learn, которая написана на языке программирования Python.
В связи с тем, что используемый набор данных достаточно небольшой, необходимо оценить качество классификации на кросс-валидации. Рассмотрим результаты экспериментов при двух подходах классификации текстов для k=5.
Таблица 1. Результаты классификации при двух подходах: BOW и TF-IDF
| Методы | DT | RF | LogReg | KNN | SVM | MLP |
| BOW | 0,79752 | 0,87615 | 0,82719 | 0,84884 | 0,86853 | 0,83146 |
| TF-IDF | 0,7916 | 0,81313 | 0,85146 | 0,89721 | 0,83636 | 0,85611 |
Из таблицы №1 можно заметить, что подход TF-IDF улучшил качество только для классификаторов логистической регрессии, k-ближайших соседей и многослойного персептрона. Самое лучшее качество классификации продемонстрировал метод k-ближайших соседей в связке с TF-IDF. Попробуем применить другой подход векторизации данных, основанный на векторном представлении слов.
Таблица 2. Результат классификации при векторном представлении слов
| Методы | DT | RF | LogReg | KNN | SVM | MLP |
| BOW | 0,85478 | 0,79194 | 0,85737 | 0,87166 | 0,89341 | 0,85559 |
| TF-IDF | 0,76944 | 0,86233 | 0,87757 | 0,86051 | 0,90995 | 0,88717 |
В целом векторное представление с помощью модели Word2Vecулучшило качество для таких методов, как дерево решений, логистическая регрессия, метод опорных векторов и многослойный персептрон. Самый лучший результат со значением меры, равной 0,909, показал метод опорных векторов со средневзвешенными векторами.
Стоит отметить, что практически все методы при различных подходах показали хороший результат. При тестировании модели Word2Vec качество классификации значительно улучшилось в сравнении с методами, основанными на подсчете слов. Причем подход со средневзвешенными векторами улучшил качество практически для всех алгоритмов. Исходя из результатов исследования, можно выделить следующие классификаторы: метод опорных векторов, k-ближайших соседей и многослойный персептрон. Они стабильно показывали хороший результат классификации – и для дальнейшей работы необходимо использовать именно их.
Для обоснования выбора алгоритма машинного обучения также необходимо провести исследования вычислительной сложности. Рассмотрим время предобработки текстовой коллекции, время векторизации данных при различных подходах, время обучения и предсказания каждого классификатора.
Таблица 3. Среднее время на обработку всей коллекции текстов
| Методы | Время, сек. |
| BOW/TF-IDF | 186,9106 |
| W2V | 255,1518 |
Для подходов BOW и TF-IDF предобработка всего набора заняла примерно 186 секунд. Так как для векторного представления слов с помощью модели Word2Vec необходим еще один этап предобработки, время увеличилось до 255 секунд. Рассмотрим среднее время, необходимое для векторизации данных.
Таблица 4. Среднее время, требуемое на векторизацию данных
| Методы | Время, сек. |
| BOW | 0,23758 |
| TF-IDF | 0,24343 |
| W2V | 1,44211 |
| W2V+IDF | 3,91884 |
Векторное представление с помощью BOW и TF-IDF преобразует данные примерно за одинаковое время. Для векторизации всей коллекции текстов с помощью модели Word2Vec требуется больше времени. Подход со средневзвешенными векторами занимает практически в два раза больше времени, чем подход с построением векторов через среднее. Это связано с тем, что для определения веса вектора необходимо определить значение IDF для каждого слова.
Далее рассмотрим значения среднего времени в секундах на обучение классификаторов и среднего времени предсказания.
Таблица 5. Среднее время на обучение классификаторов
| Методы | DT | RF | LogReg | KNN | SVM | MLP |
| BOW | 0,00219 | 0,06493 | 0,01892 | 0,00057 | 0,01572 | 0,25308 |
| TF-IDF | 0,00221 | 0,07184 | 0,004 | 0,0005 | 0,02028 | 1,04966 |
| W2V | 0,00279 | 0,07067 | 0,00265 | 0,00123 | 0,0018 | 0,11759 |
| W2V+IDF | 0,00113 | 0,07116 | 0,0029 | 0,00066 | 0,00114 | 0,12838 |
Таблица 6. Среднее время на предсказание классификаторов
| Методы | DT | RF | LogReg | KNN | SVM | MLP |
| BOW | 0,00032 | 0,00754 | 0,00024 | 0,00707 | 0,00185 | 0,00054 |
| TF-IDF | 0,00043 | 0,00797 | 0,00021 | 0,00266 | 0,00358 | 0,00068 |
| W2V | 0,00061 | 0,00628 | 0,00032 | 0,00139 | 0,00034 | 0,00051 |
| W2V+IDF | 0,00013 | 0,00589 | 0,00019 | 0,00124 | 0,00021 | 0,00024 |
Для каждого классификатора при различном векторном представлении время обучения и предсказания отличалось. Из таблицы № 1 можно заметить, что классификатор многослойный персептрон требует в разы больше времени на обучение в сравнении с другими алгоритмами машинного обучения. Однако времени на предсказание ему требовалось меньше, чем методу случайный лес. Также стоит отметить результаты таких методов, как k-ближайших соседей и логистическая регрессия. Метод k-ближайших соседей продемонстрировал самое меленькое время обучения при всех подходах векторизации данных. Логистическая регрессия продемонстрировала лучшее время предсказания для всех способов векторного представления, требуя примерно 0,00024 секунды.
Таким образом, при тестировании модели Word2Vec время на обучение и на предсказание всех классификаторов сократилось в сравнении с методами, основанными на подсчете слов. С одной стороны, время на подготовку и векторизации данных для модели Word2Vec требуется куда больше, однако лучшую точность классификации и минимальное время для обучения демонстрирует именно этот подход.
Все компьютерные эксперименты проводились на компьютере с установленной операционной системой macOS на 4-ядерном процессоре Intel Core i5.
- Заключение
В ходе исследования на практике был применен ряд методов по предобработке, векторизации и классификации данных. Были рассмотрены такие методы классификации, как дерево решений, случайный лес, логистическая регрессия, k-ближайших соседей, метод опорных векторов и многослойный персептрон. Исходя из результатов, найден наилучший, с точки зрения технико-экономических показателей, классификатор – SVM с векторизацией данных с помощью средневзвешенных векторов. Следует отметить, что классические методы векторного представления текста также показали хорошие результаты.
Предложенный подход к классификации текстов научно-технических отчетов, предоставляемых налогоплательщиком для обоснования применения налоговых льгот к выполняемым НИР/НИОКР, будет использован для реализации в программном обеспечении системы поддержки проведения научно-технических экспертиз. Данное исследование будет продолжено в части проектирования и реализации сервиса, предоставляемого налогоплательщику для проверки предоставляемой им отчетной документации по НИР/НИОКР.
- Список литературы
[1] Decision Support System for scientific and technical expertise / Belov A.V, Bikbaev B.I., Gevondyan M.S., Levitan D.A., Panina I.Yu. // in Proceedings of the 2023 Conference of Russian Young Researches in Electrical and Electronic Engineering (EIConRus). IEEE, 2023, p.p. 188-193
[2] Налоговый кодекс Российской Федерации (часть вторая) от 05.08.2000 N 117-ФЗ (ред. от 18.03.2023) (с изм. и доп., вступ. в силу с 01.04.2023)
[3] Разработка системы анализа тональности текстовой информации / В.В. Гаршина, К.С. Калабухов, В.А. Степанцов, С.В. Смотров // Вестник ВГУ, серия: Системный анализ информационные технологии, 2017, №3.
[4] Эффективная классификация текстов на естественном языке и определение тональности речи с использованием выбранных методов машинного / Плешакова Е.С., Гатауллин С.Т., Осипов А.В., Романова Е.В., Самбуров Н.С. // обучения // Вопросы безопасности. – 2022. – No 4. – С. 1 – 14. DOI: 10.25136/2409-7543.2022.4.38658
[5] О некоторых подходах к решению задачи классификации текстов по тональности на примере анализа англоязычных отзывов / Е.Р. Болтачева, C.А. Никитина // Вестник кибернетики. – 2022. – №2 (46).
[6] Анализ методов машинного обучения на примере задачи многоклассовой классификации текста / М.В. Лаптев // Информатика: проблемы, методы, технологии. – 2022. – С. 1155-1163.
[7] Анализ тональности коротких текстовых сообщений / О.В. Оглезнева // Информационные технологии. Проблемы и решения. – 2020. – № 2(11). – С.113-118.
[8] Применение BERT для классификации сообщений в службу поддержки SAP / С.С. Масленникова, В.В. Коротков // Информатика: проблемы, методы, технологии. – 2022. – С. 1164 – 1170.
[9] BERT для анализа тональности длинных текстов на примере Kaggle Russian News Dataset / Н.Д. Кропанев, А.В. Котельникова // Общество. Наука. Инновации. – 2021. – С. 256-259.
[10] Классификация научных текстов по специальностям методами машинного обучения / Б.И. Беруз, М. Тропманн-Фрик // Вестник НГУ. Серия: Информационные технологии. 2022. Т. 20, No 2. С. 27–36. DOI 10.25205/1818- 7900-2022-20-2-27-36
Авторы: А.В. Белов, профессор, email: avbelov@hse.ru; Э.А. Егорова, студент, email: eaegorova_8@edu.hse.ru. Национальный исследовательской университет «Высшая школа экономики», Москва.